States with new poll data since the last update: Florida, Illinois, Pennsylvania, New Hampshire, Ohio, North Carolina, Nevada, New York, Texas, California, New Jersey, Minnesota, Georgia, North Carolina, Indiana, Arizona, Missouri, Massachusetts, Virginia, Tennessee, Washington, Michigan, Wisconsin, Mississippi, Oklahoma, Idaho, Maryland, Oregon, Maine (All), Louisiana, Colorado, Iowa, Nebraska (All), South Carolina, Alabama, West Virginia, Kansas, Kentucky, Utah, Arkansas, Connecticut, Delaware, New Mexico, Montana, Alaska
Wow, that is a lot of new polls. While there were some others, the big influence today is that Reuters/Ipsos has started to do a weekly nationwide tracking poll where they provide state breakdowns for any state where they have enough data. So from now until the election we should start getting regular data on a lot of states that usually don’t get polled.
As usual, most of the updates didn’t change the status of the model, but a few did, and all of these moves this time were toward Trump. Lets take a look state by state:
Arizona [11 EV]
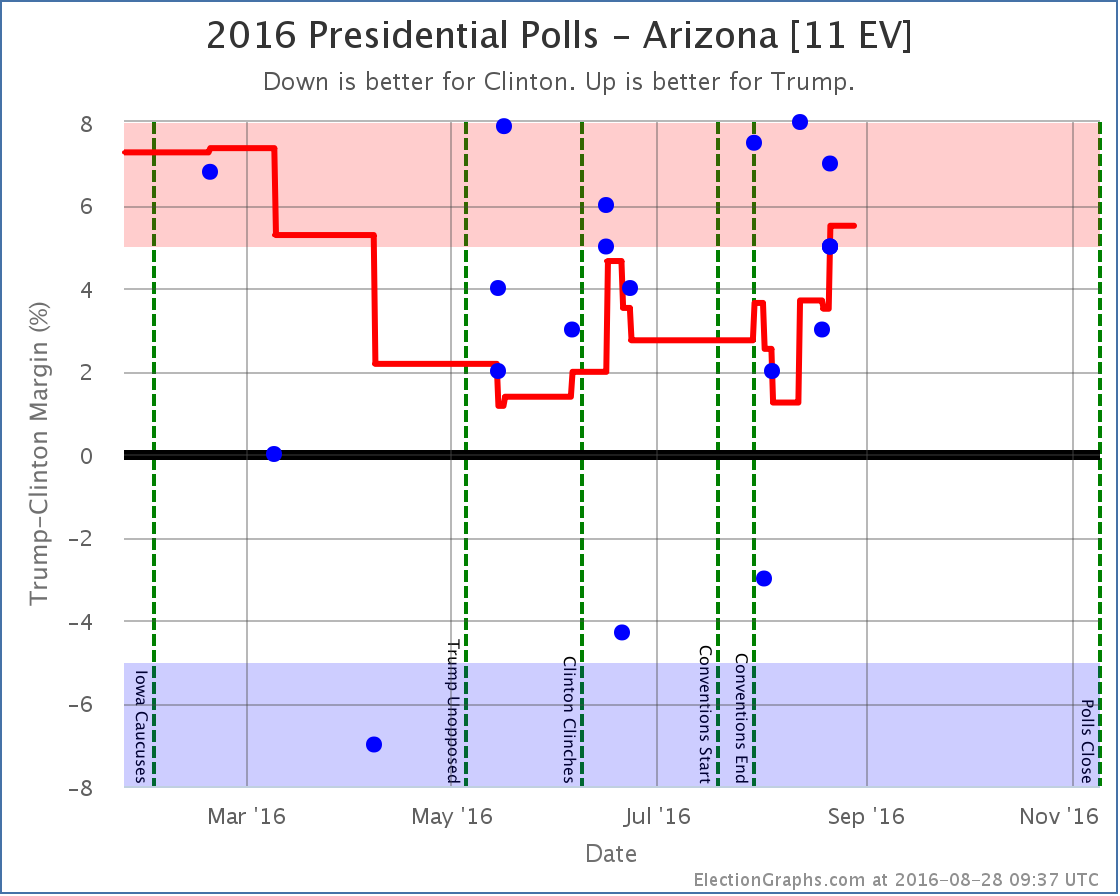
Ever since April Arizona has been looking like a possible target for Clinton… Trump ahead, but with only a narrow lead that Clinton might be able to flip. With the latest updates, Trump’s lead in the average increases to 5.5%, so we take it out of that category. The notion of a blue Arizona slips away from Clinton.
New Hampshire [4 EV]
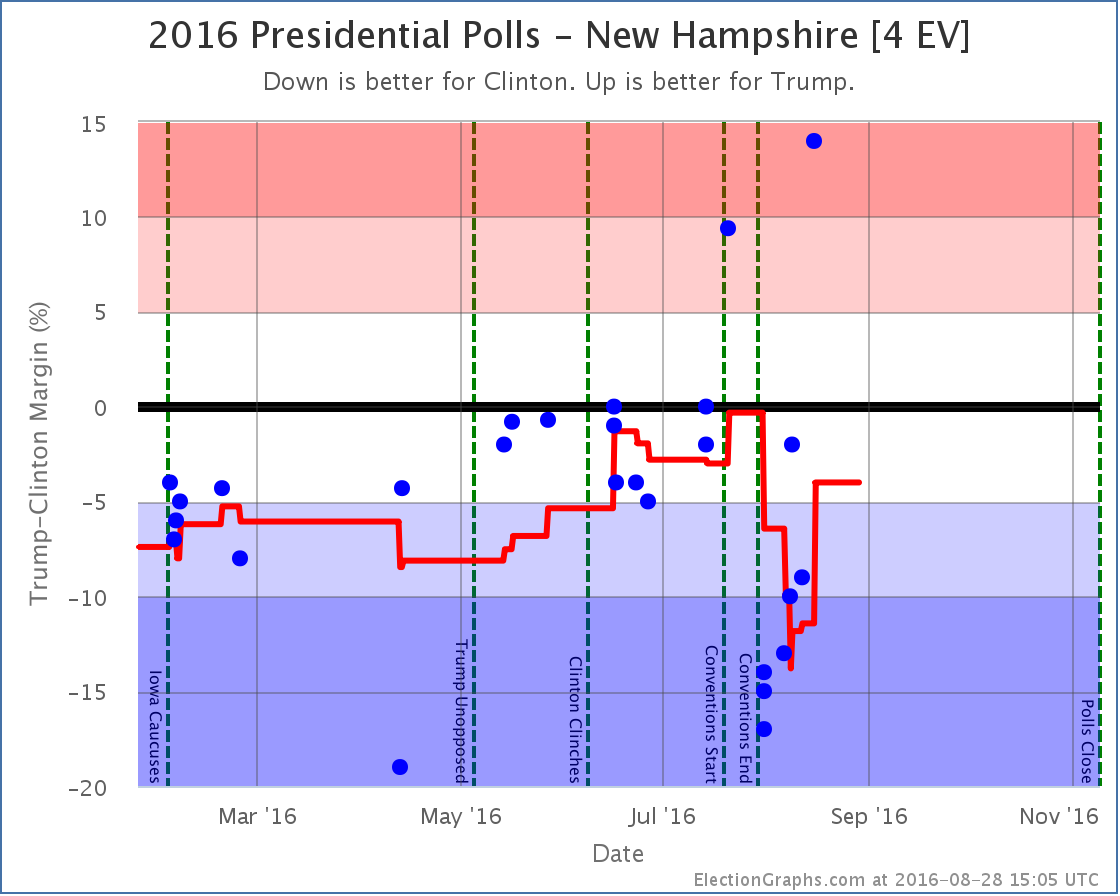
Honestly, it looks like an outlier, but the most recent of those Reuters/Ipsos results I mentioned show Trump with a huge 14% lead in New Hampshire. The second best number in the average shows Clinton up by 2%, and that is also from Ipsos. All the other recent numbers in New Hampshire show a Clinton lead of at least 9%, and there has been no radical change in the campaign that would indicate a huge swing would be expected.
If these two Ipsos data points are really outliers, then new polls should quickly show that. For the moment though, the average moves to only a 4.0% Clinton lead due to the two Ipsos data points, so New Hampshire is once again categorized as a state Trump has a chance in.
Maine (All) [2 EV]
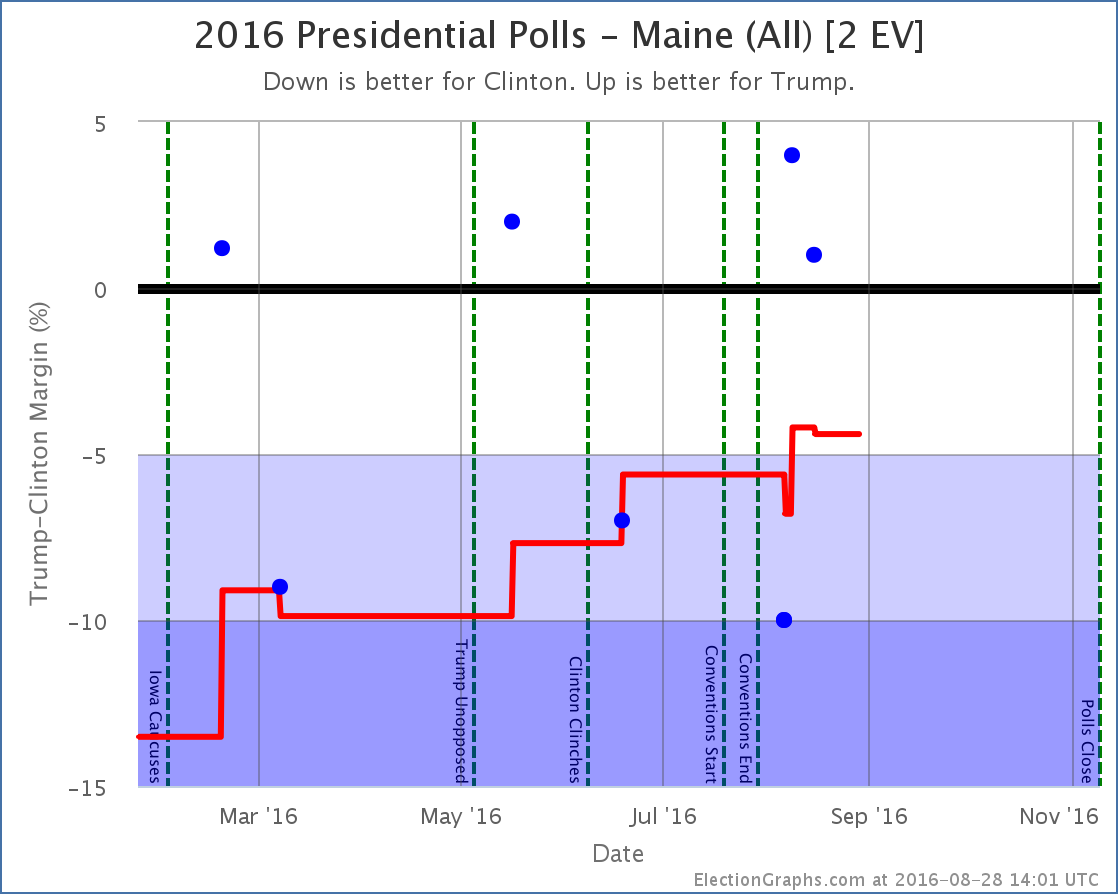
Maine has been pretty sparsely polled this Election cycle, but what polls we do have show the state trending away from being a solid blue state to being close. The latest couple of results (both Ipsos) have Trump ahead, as have a few previous polls. The average is now only a 4.4% Clinton lead, so Maine is now in the “Weak Clinton” category, and it is included in Trump’s best case.
Now, Maine is one of the two states that splits electoral votes. For winning Maine at large, you only get 2 electoral votes. You then get 1 electoral vote for winning each congressional district. Now, mathematically, for Maine as a whole to have a 4.4% lead for Clinton, Trump would have to be doing even better than that in one of the two congressional districts. But right now the average in CD-1 is a 15.8% Clinton lead and in CD-2 it is a 5.3% Clinton lead. That can’t be! You would expect CD-2 to be Weak Clinton as well, or possibly even Weak Trump.
The problem is that while there has been very limited polling of Maine as a whole, there has been even less polling of Maine at a Congressional District level. There has only been ONE poll of Maine CD-2 this election cycle. It was in June and showed Trump up by 1%. The average is 5.3% Clinton because in order to fill out the average when there are less than five polls, I use previous election results.
New polling in Maine CD-2 is currently what I classify as the “Most Needed Poll” (followed be NE-2, NE-1, ME-1 and SD). Right now we don’t have enough polling evidence to show that CD-2 is actually Weak Clinton or Weak Trump rather than Strong Clinton, but given where Maine as a whole is, the ME-2 electoral vote has to be a possible pick up for Trump too, but it won’t be categorized that way here until there are enough polls backing that up directly.
National View
Before showing the new national trend chart and tipping point charts, a quick note. In addition to the new polls added in the most recent batch, I found a handful of older polls that I had somehow missed earlier in the year. These don’t change the current picture, but they change the past. Specifically, Trump’s position in the spring was significantly weaker than it looked at the time, mainly because Florida would have slipped out of his reach significantly earlier.
To be transparent on this change, rather than just show the new charts, I’ll show the before and after due to today’s update. First the trend chart as it appeared on Election Graphs as of the August 26th update post:
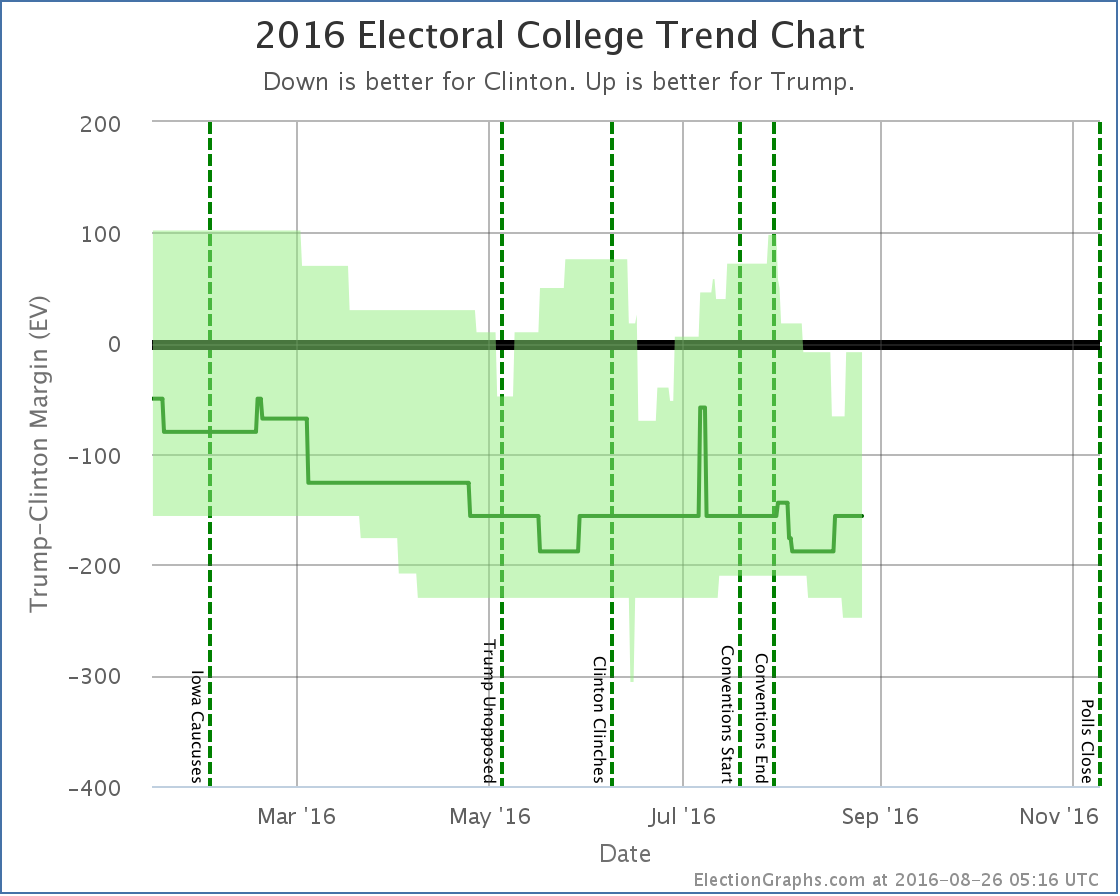
And here it is now:
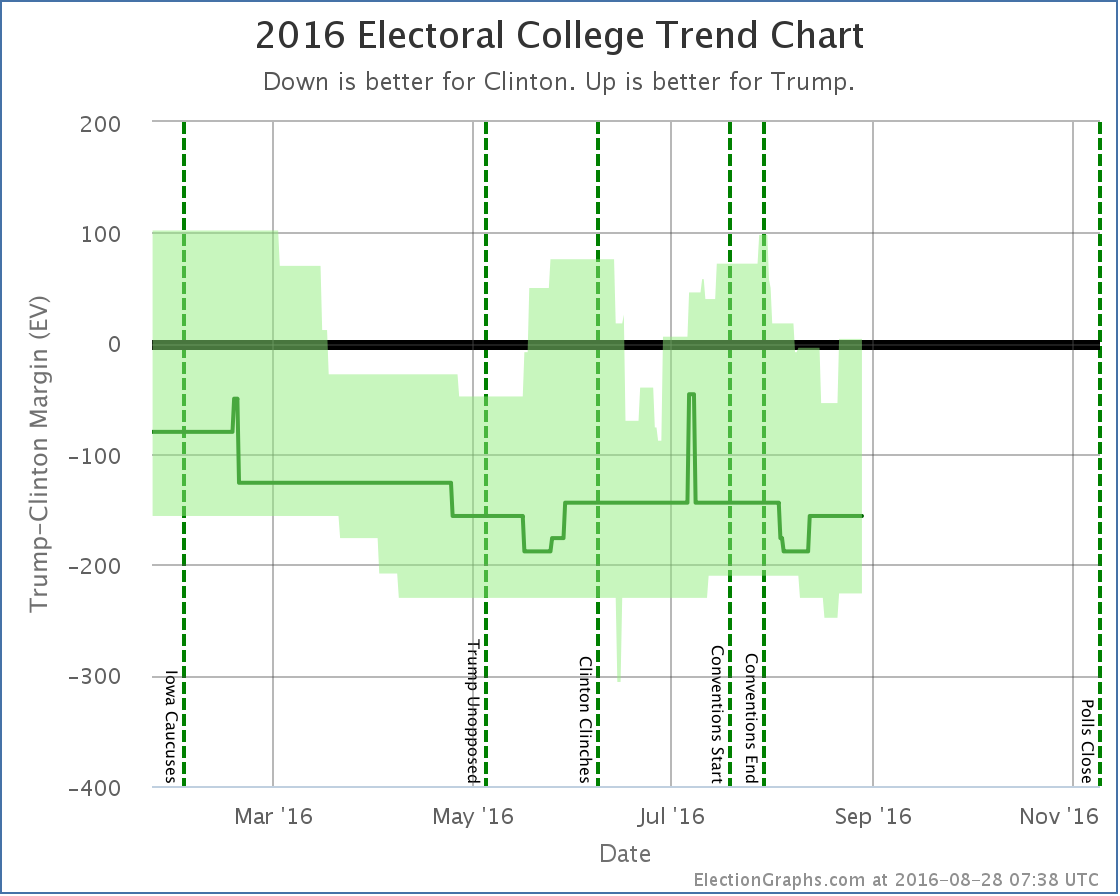
Note that in addition to the bumps upward in Clinton and Trump’s current best cases, Trump’s best case in the spring is significantly depressed, enough so that his best case moved from a narrow win in most of April to a narrow loss. There are some other subtle differences between these two caused by the addition of these old polls I had missed at the time, but that is the big one, caused essentially by one March poll in Florida that I did not see until August. Apologies for that.
The difference in the tipping point graph is even more dramatic, with Florida worse for Trump than it previously looked, there was a lot more room for the tipping point to wiggle, and it was a lot worse during the spring than it looked.
Here is the before picture of the tipping point graph from the August 26th update post:
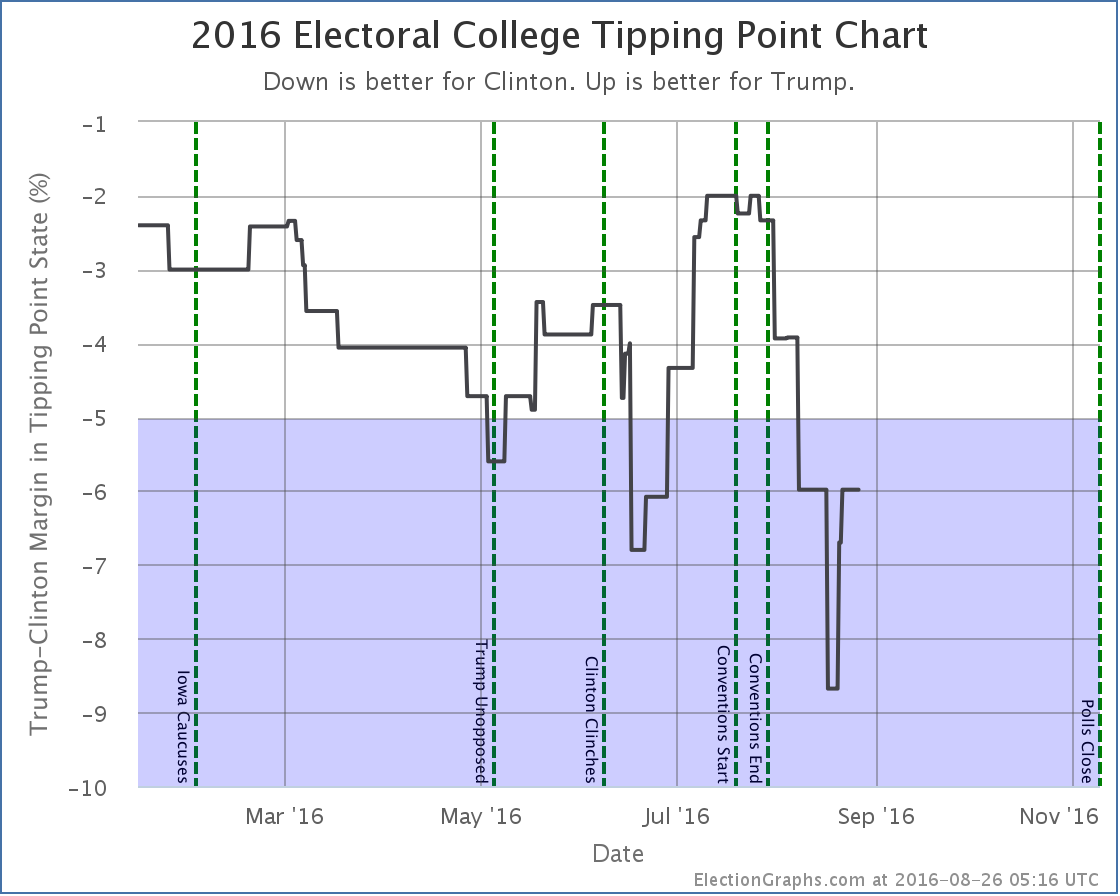
And here is the tipping point graph now:
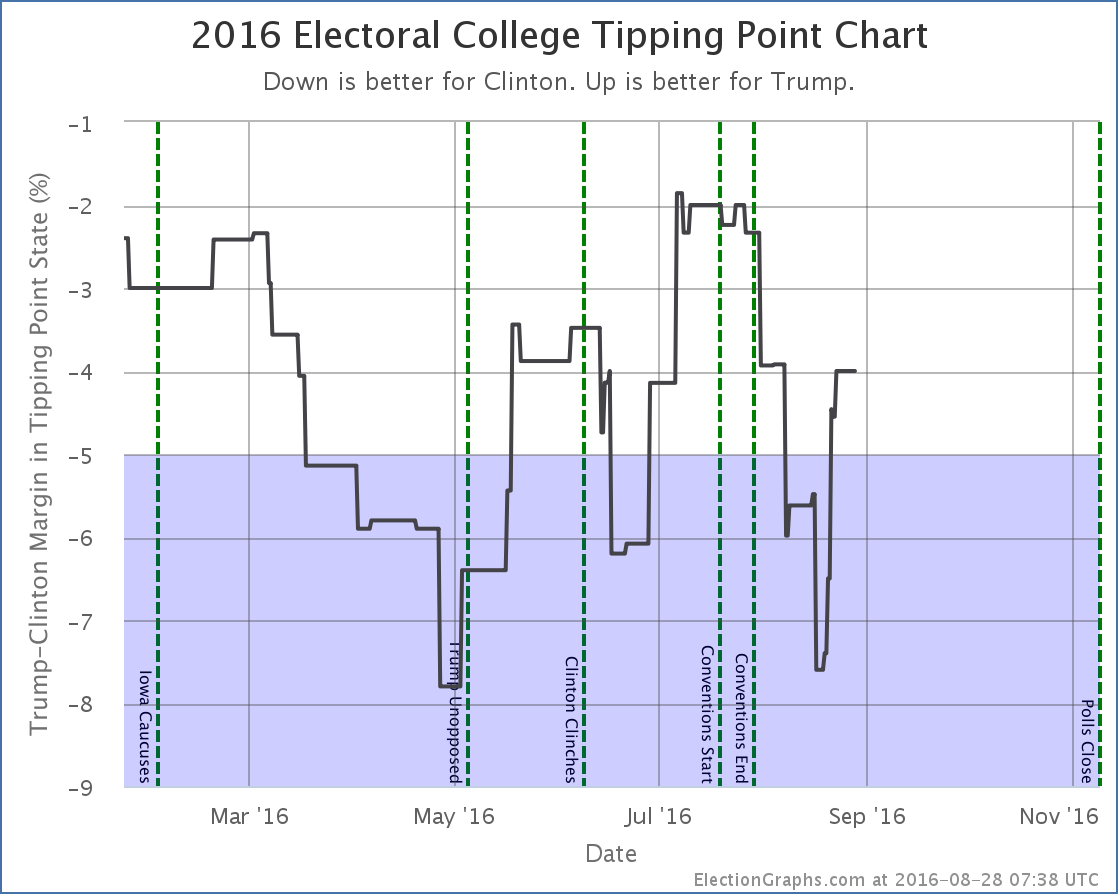
Again the main impact is that the “missing polls” that I added make it clear that Trump was significantly worse off in the spring than I had shown at the time. In fact, it means that at the end of April he was actually below his recent bottom in mid-August.
There were only a handful of polls missed, but this goes to show that even with poll averaging, individual polls in critical states can make a big difference in the overall picture. (Especially when they appear to be outliers, such as the one Florida poll I missed that made the biggest difference. Oops.)
OK, enough hand wringing about things that may have been missed in the spring.
The big current news on the tipping point is that with changes in the averages in Michigan, New Hampshire, and Ohio, the tipping point comes roaring back in Trump’s direction. In this update it moves from a 6.0% Clinton lead in Connecticut to a 4.0% Clinton lead in New Hampshire, but this is a full 3.6% swing toward Trump since his low of 7.6% about 10 days ago.
Now, everything above still shows a Trump loss, but it is looking a lot closer than it did a couple weeks ago. The first part of August was disastrous for Trump, but he has been bouncing back since then. He is still very far behind, but maybe his latest reworking of his campaign is working. His best case is once again to win, although by a very narrow 4 electoral vote margin.
Will the recent trend continue and make this race look even closer? 72.2 days left for him to do it.
Notice on Methodology: In my August 13th update I solicited opinions on possibly changing how this site deals with the case when a pollster releases multiple results from a single poll. See the discussion in that comment thread for more details. Immediately after this post goes live I will be working to change the site logic so that if two results are released from a poll, each counts as only half a poll for purposes of the averages here. Similar logic will apply to tracking polls where samples overlap, but not completely, with polls weighted to reflect the fraction of the new result that is actually from a fresh sample.
As examples of the impact this could have, the three states mentioned in this post would change as follows: Arizona is a 5.5% Trump lead (Strong Trump) with the current logic, it would be a 3.9% Trump lead (Weak Trump) with the new logic. New Hampshire would move from a 4.0% Clinton lead (Weak Clinton) to a 8.4% Clinton lead (Strong Clinton). Maine (All) would move from a 4.4% Clinton lead (Weak Clinton) to a 3.7% Clinton lead (Weak Clinton). With these three examples, two of the changes favor Clinton, and one favors Trump.
At this point I will not be adding new polls to the averages until the math changes are complete and I have reported on the results with a blog post. (Unless my revisions fail and I’m forced to reschedule for another weekend.)
[Note added 21:39 UTC – Actually, as I’m starting in, I realize that tracking polls have a bunch of extra complications that multiple results in a single poll don’t have, so I’ll leave them alone and treat them as if they were completely independent for now. Without weighting tracking polls, the changes above would now be: AZ Trump +5.5% -> Trump +3.1%, NH Clinton +4.0% -> Clinton +4.0% (No change), ME-All Clinton +4.4% -> Clinton +2.0%.]
Note: This post is an update based on the data on ElectionGraphs.com. Election Graphs tracks both a poll based estimate of the Electoral College and a numbers based look at the Delegate Races. All of the charts and graphs seen in this post are from that site. Additional graphs, charts and raw data can be found there. Follow @ElectionGraphs on Twitter or like Election Graphs on Facebook to see announcements of updates or to join the conversation. For those interested in individual general election poll updates, follow @ElecCollPolls on Twitter for all the polls as they are added. If you find the information in these posts interesting or useful, please consider visiting the tip jar.
[Blog Post] Electoral College: Trump Bouncing Back https://t.co/y8xrkkCQq7
RT @ElectionGraphs: [Blog Post] Electoral College: Trump Bouncing Back https://t.co/y8xrkkCQq7
RT @ElectionGraphs: [Blog Post] Electoral College: Trump Bouncing Back https://t.co/y8xrkkCQq7
Interesting note about the overlapping samples in the tracking polls. Is there a simple, succinct explanation for the math that a layperson would understand? If not, it might make sense to leave that change out.
Also, how much difference would it make in the result? To me, Election Graphs is about how much good information you can get using a simple metric. Making the metric more complex seems justified in merging multiple questions from a single poll since it seems like it has a huge impact on the quality of the results. But, can the same be said for trying to compensate for overlapping tracking polls?
I just added an extra note to the post above basically punting this problem for now, because I realized I couldn’t just treat it just like the polls with multiple results. (In a poll with multiple results, you know you either include all of them or none of them in the average at any given time, with a tracking poll you may be including only some of them.) But the basic issue is that the usual way tracking polls work is something like this: On Monday I release the results based on the calls I made from Friday through Sunday. On Tuesday I release the results based on Saturday through Monday. On Wednesday I release the results based on Sunday through Tuesday, etc. The Ipsos polls I just started including do this, but for their state results with a granularity of weeks instead of days. In either case, the problem is that the new poll actually uses a lot of the same data as the previous polls. In the case of a three day tracking poll, the new poll uses 2 days of data that were already used in yesterday’s results, plus one day of new data. So the new poll is really only 1/3 independent new data. So if you count both yesterday and today’s polls equally in an average, you are essentially double counting the days that were used in both polls.
RT @abulsme: [Blog Post] Electoral College: Trump Bouncing Back https://t.co/2bB4q6Aqfg
I think I’d ignore that level of detail as far as tracking polls, after all that’s the way they are designed. You say it yourself, the results contain overlapping data, but the fact is that it’s the results you are using instead of the cross tabs.
In the case of daily tracking, you can either just have each day/week result knock off the previous result from that pollster. This removes any weighting concerns but means that more recent results will be ignored .
Alternatively, you could effectively track the tracking poll and keep multiple results but weight them as per multiple results from a single pollster.
I know this second option means some days/weeks results may be used multiple times and goes back to the overweighting problem. However, unless you’re going to cause yourself a nervous breakdown by carving up every single tracking poll for the next couple of months…
The final point is just a decision as to if you class a weekly poll and daily poll from the same pollster as being from the same pollster, as in do you weight them individually or combine them. I’d be tempted to separate daily and weekly polls but I don’t know.
Any help?
I just finished changing everything to do the re-weighting we have been discussing for single polls that release multiple results and it took me almost three days, so my inclination at the moment is to not do anything special at all with tracking polls right now, unless they start to really cause problems. Right now there was one tracking poll back in New Hampshire in the run up to the primary there, and now the Ipsos polls. I’m sure one or two swing states will get daily tracking polls as we get into October though.
Last cycle I remember some trackers dealt with this by not including every day’s tracking poll, but would ignore them until one came out that was completely independent of the last one they included. That is one possibility, but of course it would just seem like it was missing some of the results. This would often not have the “latest” results though. Of course, you could always keep the latest and adjust which older ones you had, but that seems complex. I’m not sure I like these solutions.
I backed off from just using the weighting solution at the same time I added what I did over the last few days, because I realized you would have to not just set a weight for each data point, but vary that weight depending on the presence or absence of other points from the same tracker in the average at any given time. That is, if the “five poll average” only contains the very latest result from the tracker, that point should be given full weight, but if it includes two or three, then they should be weighted by how much they overlap. Again, getting much more complex than I really want to deal with.
If the trackers really seem to be an issue, I can revisit. But I think we’re really getting into secondary level adjustments, maybe even tertiary level at this point. Any adjustment to the detailed rules I use to compute the average will jiggle things around a bit, but will be unlikely to change the overall picture all that much. (Although of course a state like Florida moving from +0.1% Clinton to +0.1% Trump makes a big difference in the Electoral College picture.)
So I think for the moment I’m going to try to avoid overthinking the details of how each tracker works to try to compensate for the overlap and just treat them as if they were independent.
We will see. I’ll of course keep thinking about it, and if any of you have additional thoughts I would love to hear them.
Thanks for all the input on the multiple results issue. Hope you like how the change is reflected.
Please correct me if I’m talking rubbish, but how about something like this for an idea. I know it’s extremely simplistic. I’ll do this by an example..
If you take a three day tracking poll and only use the most recent three results you’d have the following
Day 1/2/3 for poll 1
Day 2/3/4 for poll 2
Day 3/4/5 for poll 3
That has the equivalent of 5 days results, so if poll 3 is given weight for each full day and polls 1 and 2 only receive weight for partial.
Poll 3 – 60%
Poll 2 – 20%
Poll 1 – 20%
I know there are other permutations, but weighting the most recent one highest and others equally seems the easiest.
Obviously using different bases of trackers and amount of days means different percentage weights, but you hopefully get the idea.
Actually, I may be being extremely stupid…
Isn’t a tracking poll, by definition, already a weighted series of daily polls?
In which case the solution is very simple.
Only allow one tracker per pollster in any average and treat it independently of other polls from the same company.
I know this means a pollster can again have two results in the averages, but given that trackers and standard polls are different beasts then surely it’s reasonable to do it this way.
Hi Richard, You are right that if you have a 3 day tracker poll a good way of weighting them would be to give full credit to one, then weight others as 1/3 since they only have 1/3 new information.
What makes it harder than the multiple results in one poll case, is that you can’t just assign a weight at the time you find out about the poll and then leave it fixed forever, because the weighting needs to depend on what else is currently included in the average. And if you are giving the most weight to the most recent then you have to retroactively change the weights whenever a new poll is added. So the poll that comes out on Tuesday counts as a full poll on Tuesday, but gets downgraded to a third of a poll on Wednesday. That’s if you give the most credit to the most recent rather than some other method of distributing the weight, but all methods of distributing the weight have similar problems in that the weight can’t be fixed forever, it has to depend on what else is in the average. Which makes things more complex to understand and to code.
The other suggestion you make essentially is the same thing, but allowing some weights to be zero by only allowing one result in the average. In this case when the poll comes out Tuesday you give it full credit, but as soon as the Wednesday result comes out you demote it to a zero weight (in favor of the new result).
In both these cases you can no longer just say “I want the last five polls (taking into account their weights)”, you have to start adding logic that in some situations polls count more or less depending on what else is currently included in the average.
All this kind of thing CAN be done of course. I spent some time this weekend thinking about how I was going to do that if I felt it was needed. But at that point we are getting fancier and fancier with the logic and getting further and further away from the original “hey, look, you can get pretty good results from a simple average, you don’t need to have complex and inscrutable methods” original idea of this site.
If you don’t do SOMETHING with the tracking polls it technically is giving extra weight to the overlapping results, just like the pollsters reporting multiple results were getting extra weight. But it might be something that just doesn’t make that big a difference for now. (Crossing fingers.) If it REALLY became a problem, I might end up solving it with the most low tech method, just not including a new tracking poll result if it overlapped with the last one I had already included. This ensures independence, does not require any logic changes, and doesn’t require you to change which polls you include or how much you weight them over time. Of course, ignoring that new data while waiting for the next non-overlapping point would be painful, especially in the last couple weeks before the election. So I’m hoping it doesn’t become a big enough issue to make me do that. :-)
And of course, if a pollster releases multiple fully independent polls more often than another pollster (rather than tracking polls with an overlap), that pollster themselves will still be overweighted in my average, but at least the numbers will be based on completely different samples unlike the cases we have been discussing. So, for instance, if a pollster did a daily poll of South Dakota, but each covering only one day, and released the results every day, very rapidly that pollster would have all five polls in the five poll average. The results would be independent statistically, since there was no sample overlap, but you’d still have Pollster X completely controlling the average in South Dakota. I think I am OK with this, but some folks might not be. :-)
Ah, now I’m getting it. The problem is not so much what to do but how to do it!
Something that’s way, way outside my field. I don’t know anything about coding so wouldn’t have a clue where to start, sorry.
I think if you’re going for simplicity then adding tracking polls at their refresh interval to prevent overlap is probably better
Unless…
Could you not add trackers weighted like this?
Day 1 60%
Day 2 20%
Day 3 20%
Day 4 60%
Day 5 20%
Day 6 20%
Day 7 60%
That’s obviously assuming a 3 day tracker. It compensates for overlap in a basic way and means no weights need constant changing.
Again, I know what I’m trying to get at but not if I’m explaining or understanding the problem (unfortunately I’ve ASD, so don’t always catch on to things).
I admit, I have no idea how this would fit into averages with other pollsters and so on.
As to your last point. If only one pollster is covering a state it will dominate, I agree, but that’s probably better than no polling and only having outdated results to make up numbers.
My only thought there would be to note if that pollster was one that had any known issues or bias. Not change the results, just note the possibility of a house effect.
Thanks for all the thoughts Richard. If you were including all polls then you would not want to make every 4th one count more, as while it no longer overlapped with the first one, it still overlaps just as much with the one immediately before it. But the trick is, to get the right weighting you would have to not just look at all the past polls in the tracker, but be aware of exactly which ones were in the average at the moment. Lets us start out by saying it is the only pollster in a state. You have these polls:
A: Sun/Mon/Tue
B: Mon/Tue/Wed
C: Tue/Wed/Thu
D: Wed/Thu/Fri
E: Thu/Fri/Sat
We’re doing a five poll average, so one possible weight would be A gets 100% weighting, then each of the others gets 33.3% since they all have 1/3 new data, with 2/3 overlapping previous polls. That prefers the oldest poll. You could also give E the 100% and all the rest 1/3 to prefer the newest poll. There are other ways to do this too.
Now, in either case, once poll F is released covering Fri/Sat/Sun, you have to change your weightings. You can’t just drop poll A and use the existing weights when averaging the new polls. Lets look at the one where you weighted A higher for simplicity (their are similar things to say about the other ways, but they are slightly harder to think about).
If we just let A drop off and weighted F at 1/3 like we do other new polls, now no poll gets full credit for what it brings that is new to the average. We are now once again treating all these polls equally, even though some of them contain only samples that are also used in other polls included in the average, while some contain unique samples that don’t appear anywhere else (the ones on the ends).
So you have to not just set a weight for a specific poll and forget about it, you have to decide on one weight for the poll when you compute it today, another when you compute it tomorrow, etc.
This is also determined not just by the results from the actual tracking poll, but other polls you may have in the mix too. If some other pollster released a completely unrelated poll during the 5 days above, then your average is going to end up containing 4 results from the tracker, plus the other pollster. So in the case above, A would be knocked out early, and you would want to give the 100% weighting to B.
Etc.
Anyway, I had hoped to just solve this by exactly the same mechanism I used to weight the multiple results from a single pollster, but the kinds of things above mean that it wouldn’t quite work right if I did. I’d have to do something more sophisticated that determined the weight of polls on the fly rather than the weights being pre-determined by me manually when I enter a poll. “Ah, this poll reports 4 results, therefore each must be weighted as 1/4, so I’ll put that in the data file that is used to generate the site”, vs the site itself having to figure out the weightings based on looking at what polls happen to be in the average at any given time.)
That was much more complicated and I knew I didn’t have it all figured out yet, so I punted on that problem. And I suspect the difference “properly weighting” tracking polls would cause will be relatively minor in the grand scheme of things, so at this point I’m basically saying “Just treating them as independent is probably good enough.”
And no apologies for ASD or “not catching on”. My son, about to turn 7 (YouTube channel at http://alexmxela.com/ ) is also ASD, and people have accused me of having tendencies in that direction as well (although I have never actually been diagnosed as such). Seeing things a bit differently than the norm is not something to apologize for, it can be a strength. Your questions and input have been great. Glad to have you here.
I follow you, I think!
The reason I weighted extra every few days was to compensate for the previous extra weight poll dropping out. That’s way you still keep results to 100% and each day is given approximately equal weight.
That, at least, should negate the need to change weighting every day….
HOWEVER…
What % you’d use for 5 days I don’t know. I want to say divide 100% by total number of days (eg 7 for a 3 day tracker over 5 days) and then assign each poll a weight based on the number of individual results included. I don’t think it’s quite right using that method though, I’m not sure.
As for the added complexity of other pollsters.
I understand that now!
I was treating it as an individual, single, result and not as one of five.
D’OH
Apologies for that, a prime example of not quite catching on (I know you said no need for apology, but it’s somewhere between politeness and habit )
No problem Richard! Glad it makes sense now. It would be easy if tracking polls just released regular results but not with overlapping samples. But trying to do the “right thing” with overlapping samples is hard, and depends in part on the specifics of how each tracking poll operates. It just gets messy. And with me trying to “keep it simple” as one of the prime goals of the site, I’ve probably complicated things enough with the weighting for single polls with multiple results. Probably best to just take tracking polls at face value and not worry about this level of detail. :-)