After a bit of testing, on May 4th the first episode of popular Wiki of the Day launched, followed by random Wiki of the Day on the 5th, and featured Wiki of the Day on the 6th. Then I posted about it. It has now been 3 months since that first episode launched. Stretching it back to 100 days to include some of my testing, here is a look at how these fully automated podcasts I created have been doing. If you haven’t yet by the way, please subscribe!
I’ve been looking at it in terms of unique downloaders in the trailing 7 days. (Defining unique based on IP address plus user agent, excluding obvious robots… which has some flaws of course, but it will do…)
Anyway, lets look at the three podcasts…
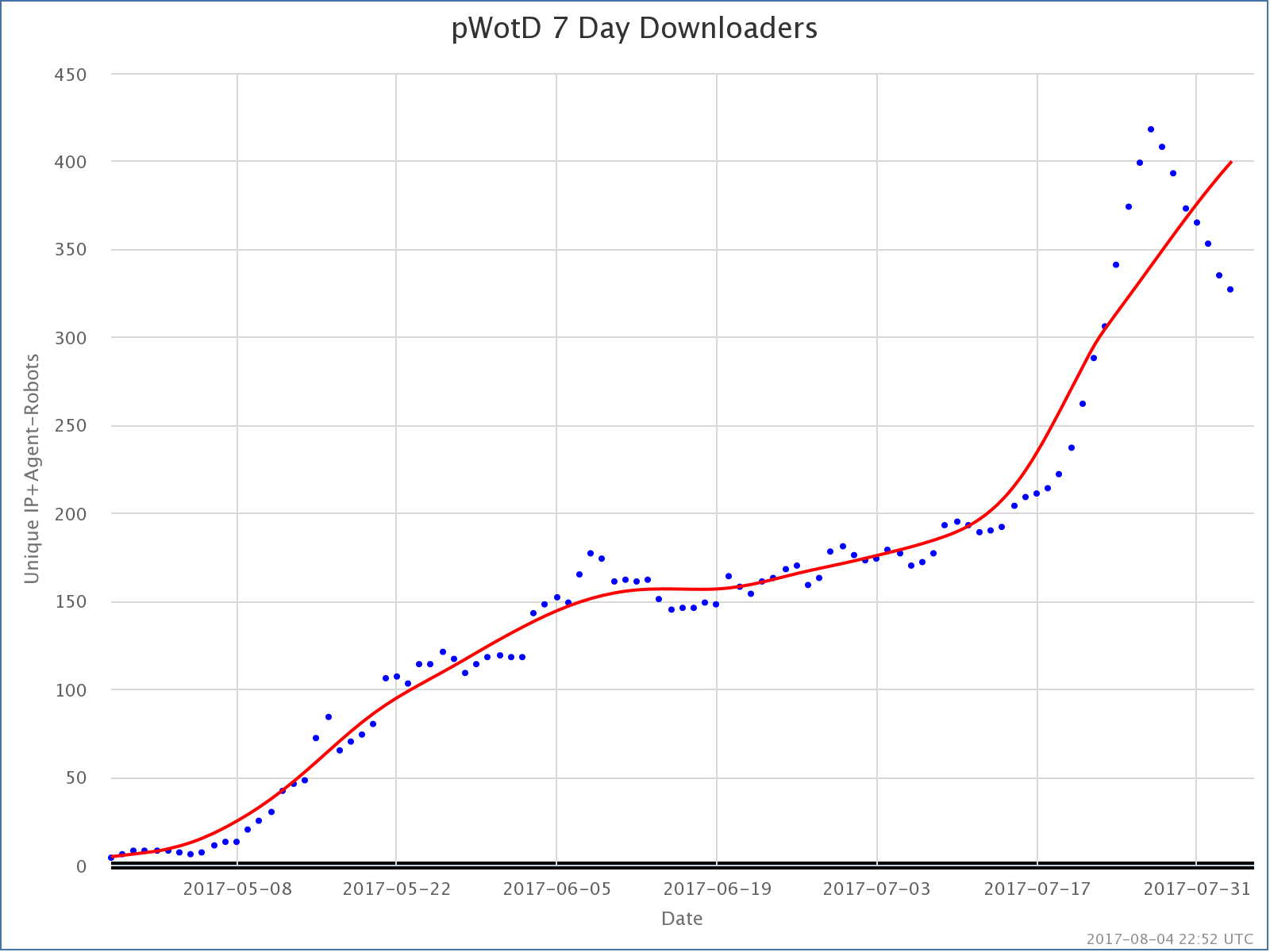
popular Wiki of the Day is by FAR the most, well, popular. It has been trending upward in terms of number of listeners pretty much from the moment it launched. There have been spikes when particularly popular episodes were released. For instance, that really obvious spike in July is due to the release of the episodes on Chester Bennington and Linkin Park. That peak isn’t over, so we’ll see if we end up back on the growth trend from before those episodes, or if the growth trend stops.
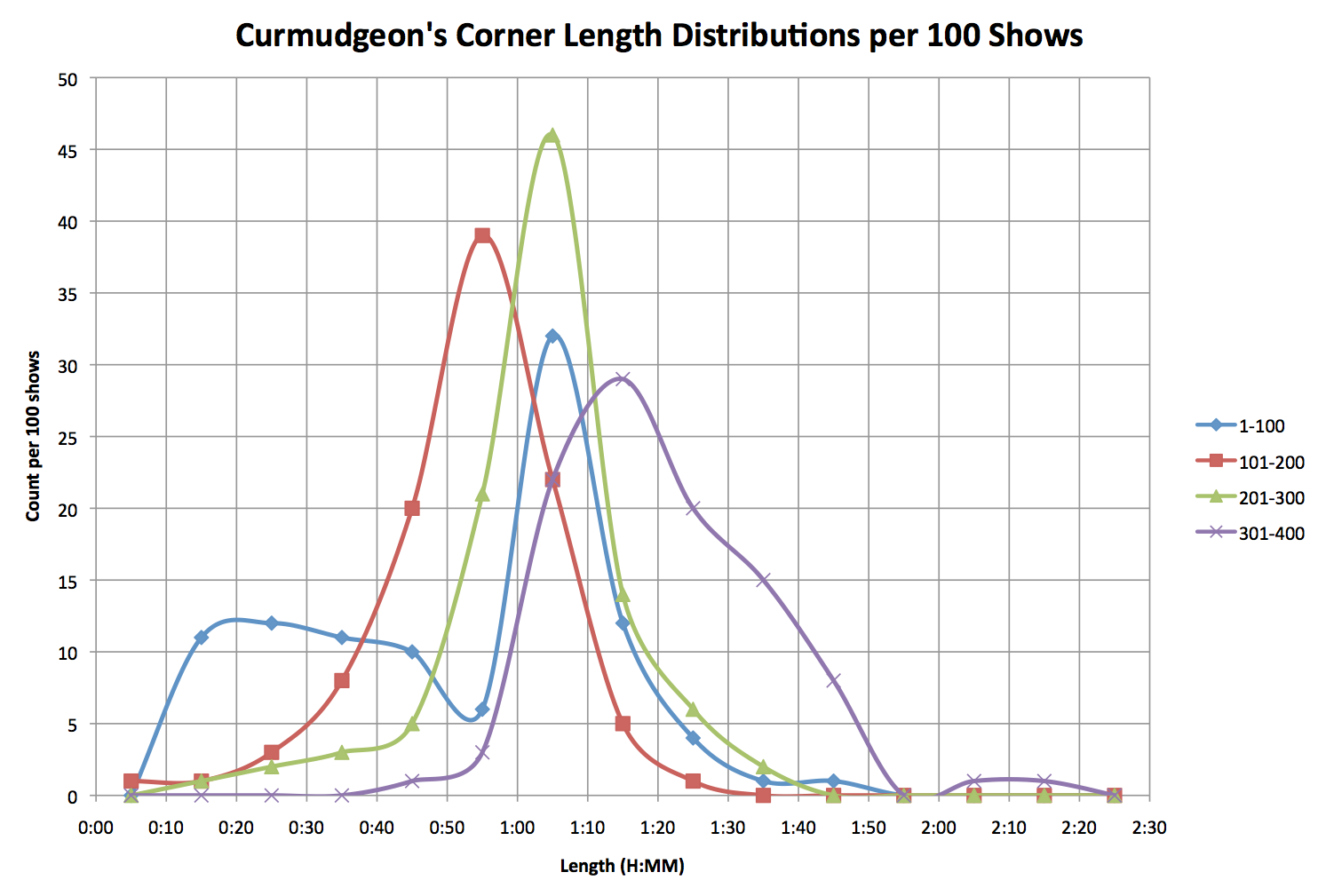
With my other podcast, Curmudgeon’s Corner, the pattern is that at any given time, most people are downloading the most recent episode, and only a few people are downloading older episodes. Just recently, in the last week or two, that has started to be the case on most days for pWotD, but for most of the last 100 days, generally speaking the latest episode would NOT be getting the downloads. Instead, a handful of episodes with nice popular search terms would be getting the most downloads.
I don’t have stats running the whole last 100 days easily available, but I regularly generate stats on downloads over the past 30 days. In the 30 days ending August 2nd, the most downloaded episodes for this podcast were:
- Justin Bieber from May 12th with 285 downloads
- Linkin Park from July 22nd with 190 downloads
- Ariana Grande from May 24th with 125 downloads
- Chester Bennington from July 21st with 102 downloads
- Ed Sheeran from June 26th with 60 downloads
There does seem to be a theme in the current top 5. They are all music related. The episodes are on all sorts of different topics, but for whatever reason those are the most popular.
In any case, the number of downloads for the podcast is growing, and we do seem to have transitioned to the current episodes being the most downloaded episodes in the day or two after they are released, so it looks like the downloads are starting to be dominated by people who are actually subscribed rather than people finding individual episodes through searches. And that is without any ongoing effort from me, or any money for advertising or anything.
So that is good.
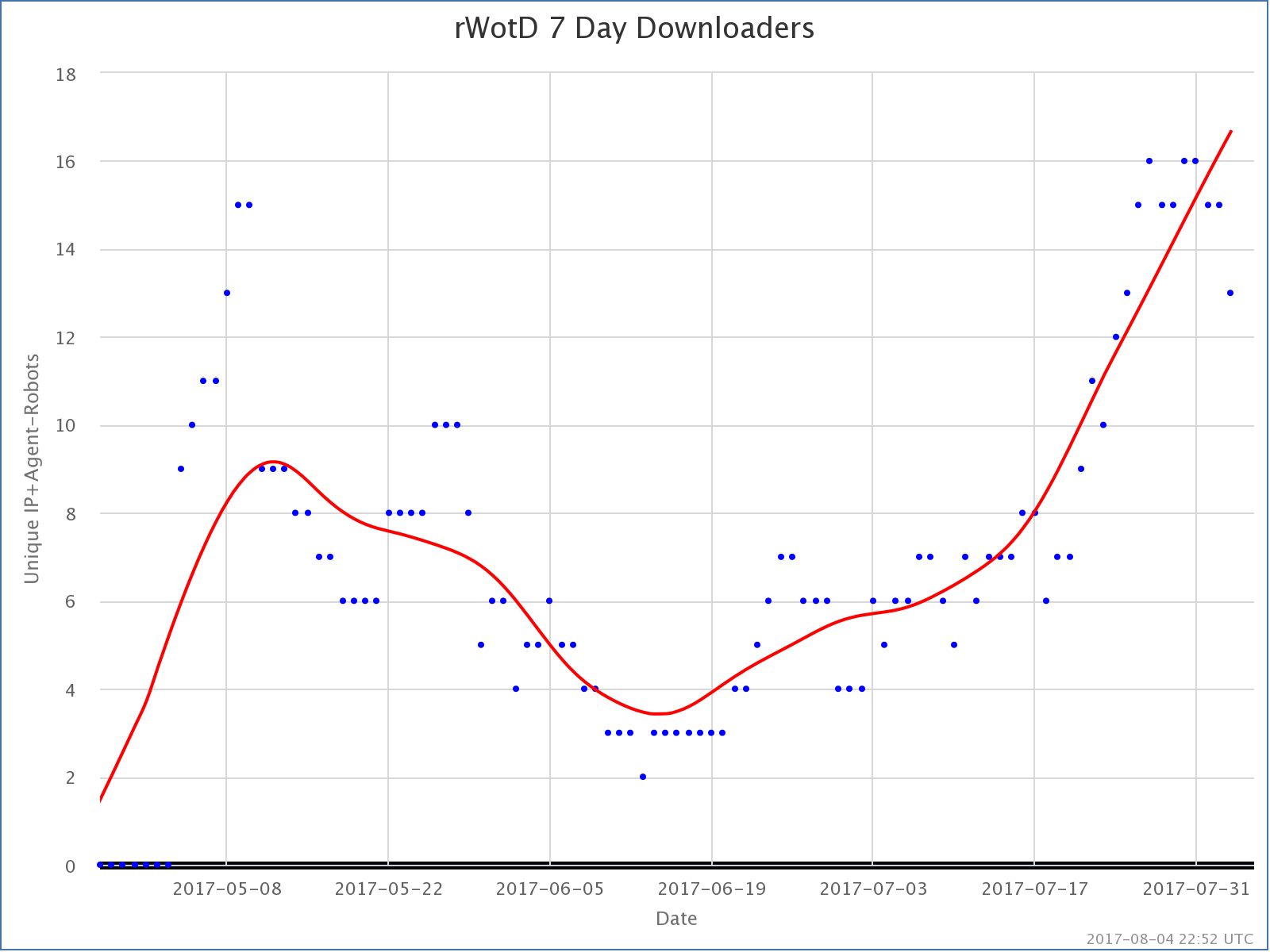
The “popular” variant really is the only one of these getting significant numbers. It is almost 24 times as popular as the next most popular of the three podcasts, which is the “random” variant, random Wiki of the Day. After the initial spike of people I know checking out the podcast, it was basically just me listening to this one. Because I listen on multiple devices while on several different networks, my metric often detects me as 3-5 different “people” over the course of a week. But in the last few weeks, random Wiki of the Day has been trending upward as well. It is still tiny, but there are a few people other than me listening.
The top 5 episodes downloaded in the last 30 days for this one are:
- Rebecca Soni from July 24th with 5 downloads
- Friar Alessandro from August 2nd with 4 downloads
- Charles Allen, Baron Allen of Kensington from July 27th with 4 downloads
- Cho U from July 26th with 4 downloads
- BГ©atrice de Planisoles from July 21st with 4 downloads
Notice all of these are very recent, no really old episodes showing up on the Top 5 list.
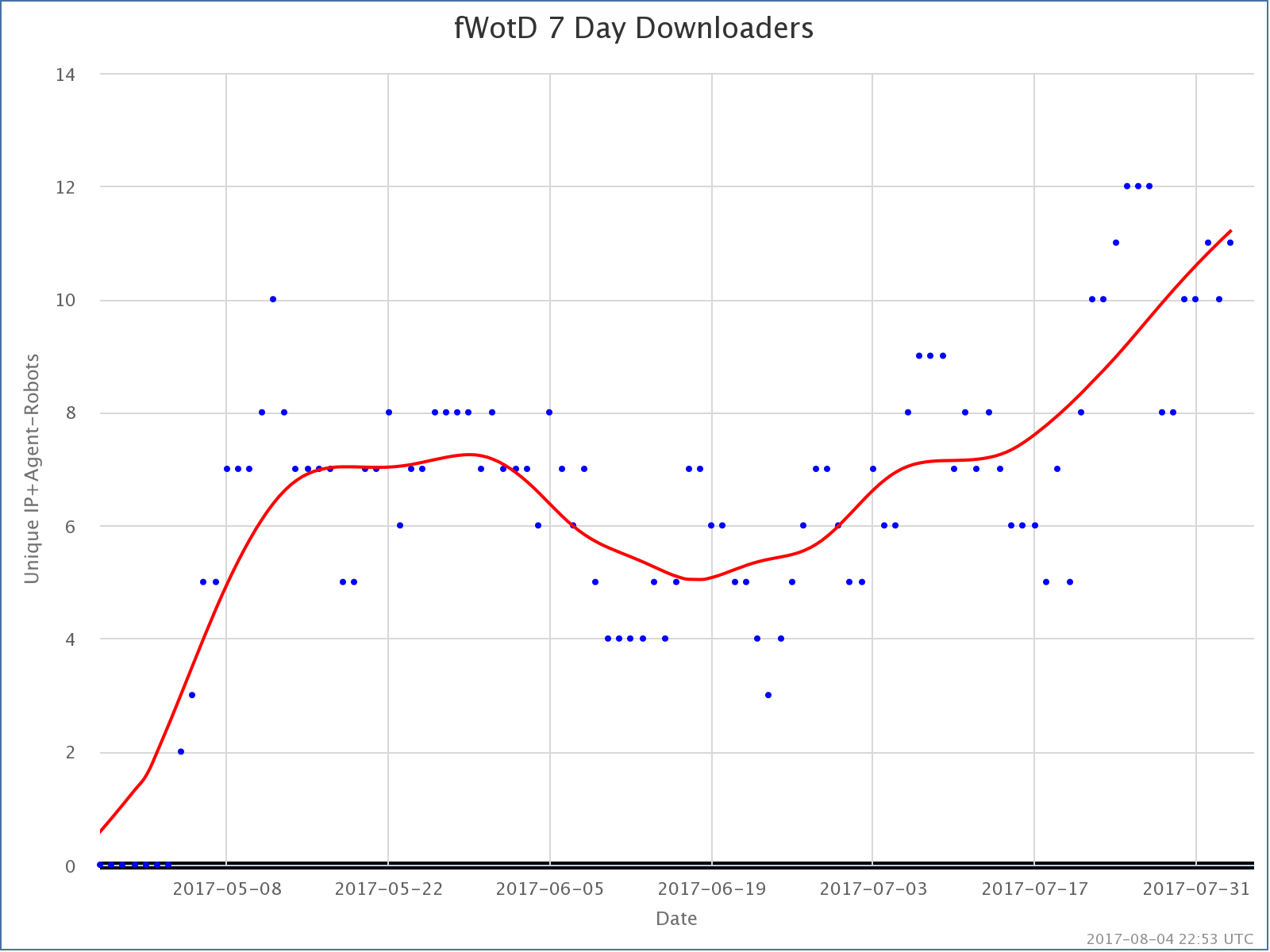
Finally, the least popular of the three, featured Wiki of the day. Least popular, but also growing slowly. A handful of people other than me are actually listening to it!
The most downloaded episodes over the last 30 days:
- The Beatles from July 7th with 4 downloads
- Murder of Dwayne Jones from July 21st with 3 downloads
- Columbia River from July 18th with 3 downloads
- Dire Wolf from July 17th with 3 downloads
- Blade Runner from July 12th with 3 downloads
And that is that. Also growing. Slowly.
Oh, and just for comparison I guess… over the same time period:
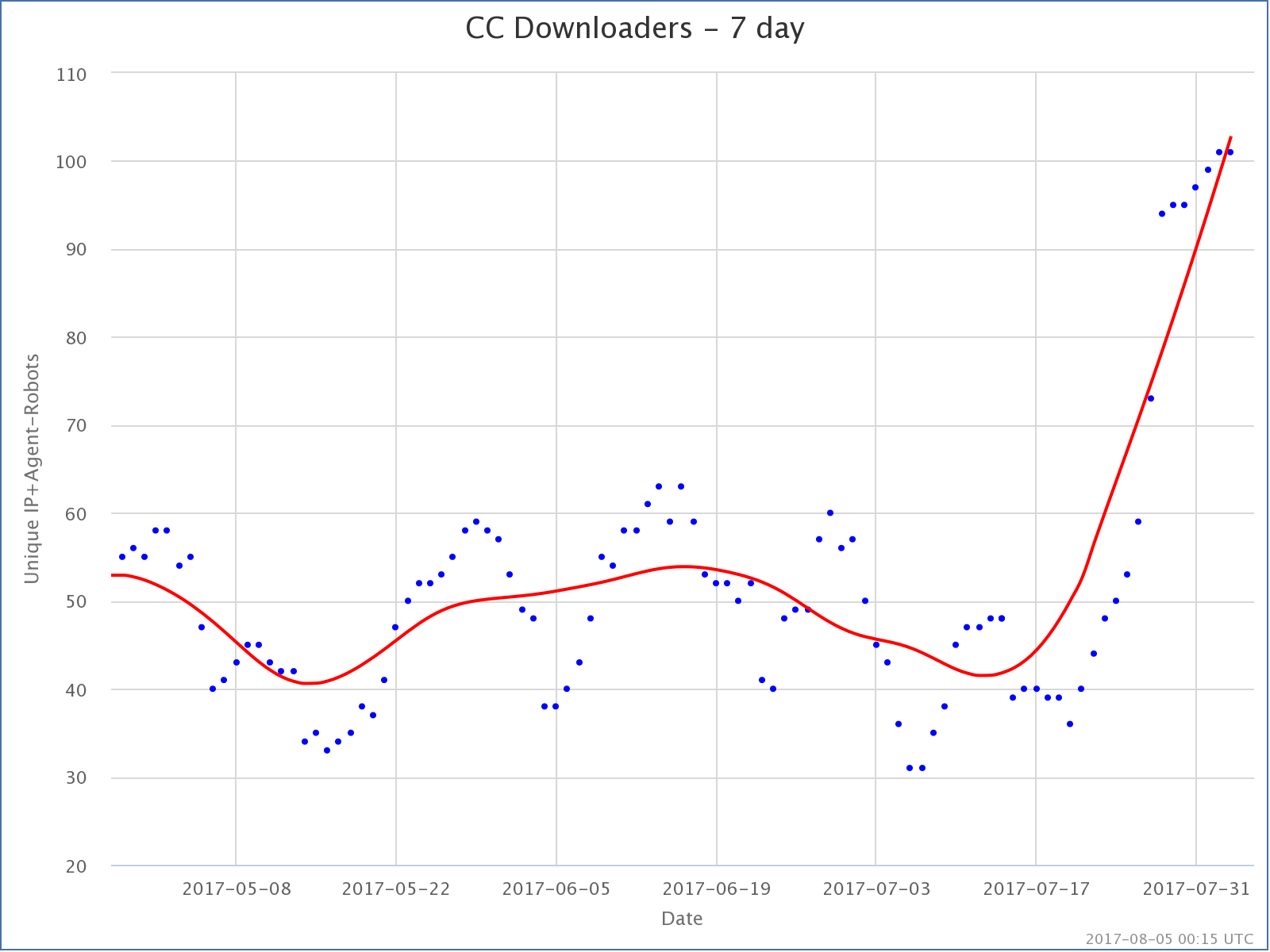
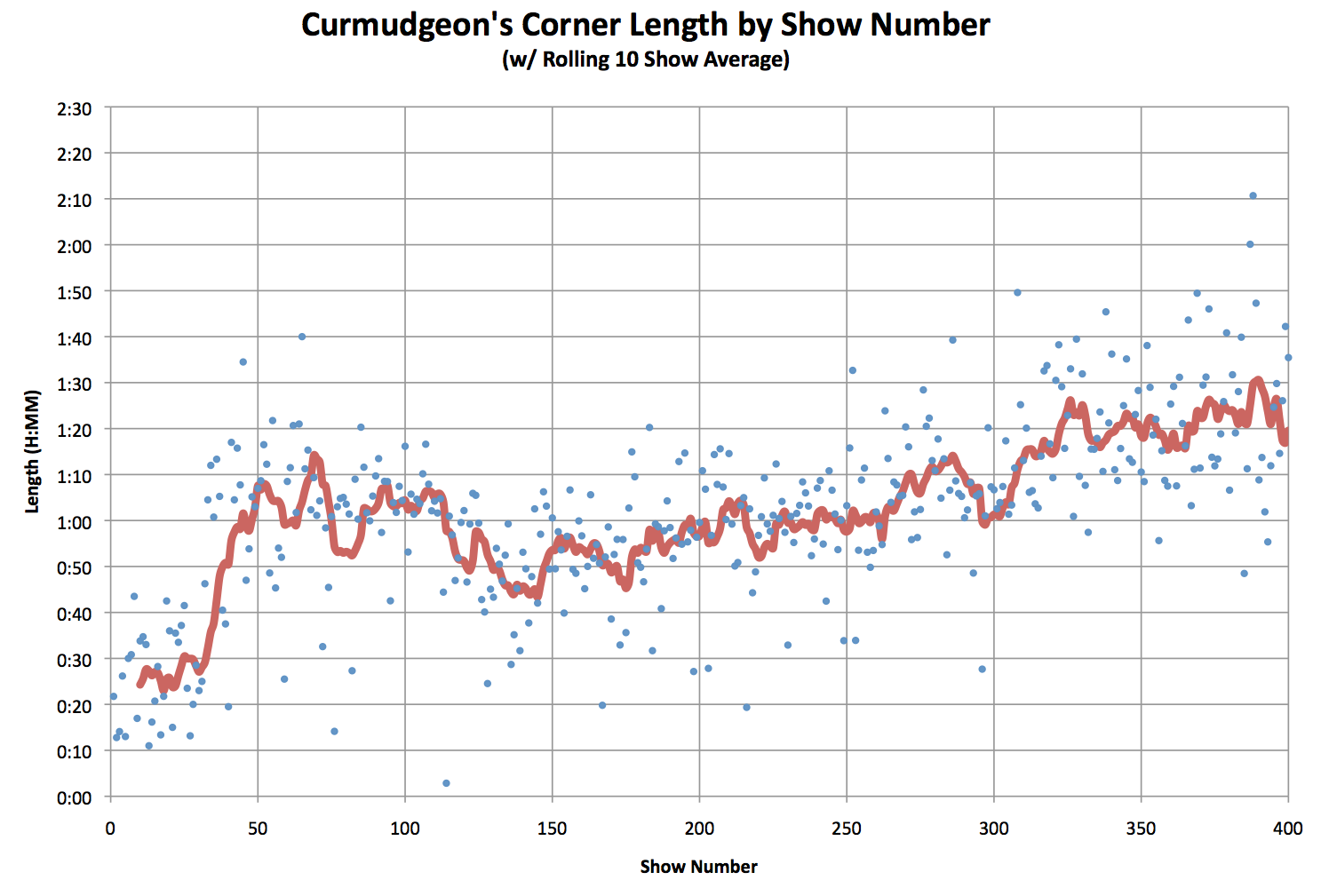
Curmudgeon’s Corner, the podcast I actually put about 5 or 6 hours a week of work into, is at about 100 downloads per week right now. That’s after a big spike we are seeing after we switched some stuff around on how we promote the podcast a couple of weeks ago. (We switched from Facebook and Google ads to an ad in Overcast, a popular podcast player.) We’re getting a bunch of new people checking us out at the moment. Don’t know if they will stick around if we turn off the ads, but for the moment the trend looks good.
Of course that is a bought and paid for trend line. And even with that popular Wiki of the day has 4 times the downloads Curmudgeon’s Corner does. Guess people just like their Wikipedia content!
I don’t actually mind this… it was actually what I hoped would happen… the automated podcasts… which each contain a promo for Curmudgeon’s Corner… slowly growing listenership via people finding them via searches and such, but with no additional promotion and no additional weekly effort on my part… and maybe pointing a few people back to Curmudgeon’s Corner. They key is now that it is set up, it is very little continuing effort on my part. I basically just check the stats periodically, and listen to the new episodes to make sure nothing breaks.
And there ya go.
Anyway. Fun stuff.